GynSurg
GynSurg is a comprehensive multi-task dataset for gynecologic laparoscopic surgery, designed to support a wide range of video-based surgical analysis tasks. GynSurg integrates high-resolution video, dense temporal annotations for surgical actions and side effects, and pixel-level segmentation masks for surgical instruments and anatomical structures. This unified dataset provides a foundation for advancing research in surgical action recognition, instrument and anatomical segmentation, intraoperative event detection, and workflow understanding. The structure and contents of each dataset subset are detailed in the following subsections.
GynSurg contains the following sub-datasets:
- Actions (Needle Passing, Coagulation, Suction/Irrigation, Transection, Rest)
- Side-Effects (Bleeding, Smoke)
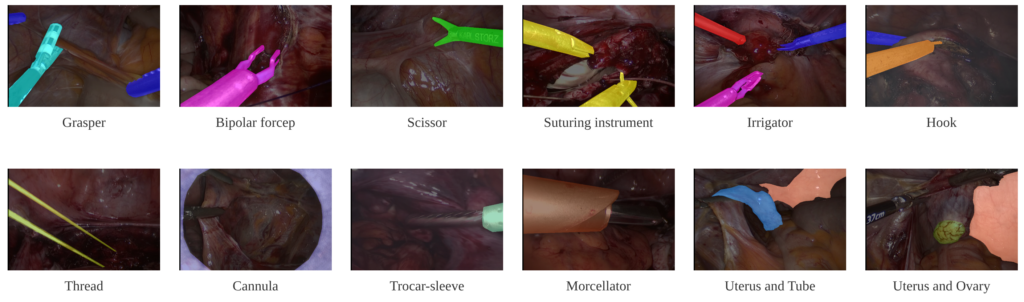
- Instruments/Tools (Grasper, Bipolar forceps, Scissors, Suturing instrument, Irrigator, Hook, Thread, Cannula, Trocar-sleeve, Morcellator)
- Anatomy (Uterus, Ovary, Fallopian Tube, general “organ”)
More information about the dataset can be found in the ACM Multimedia 2025 dataset paper.
The dataset can be downloaded here.
Cataract-1K
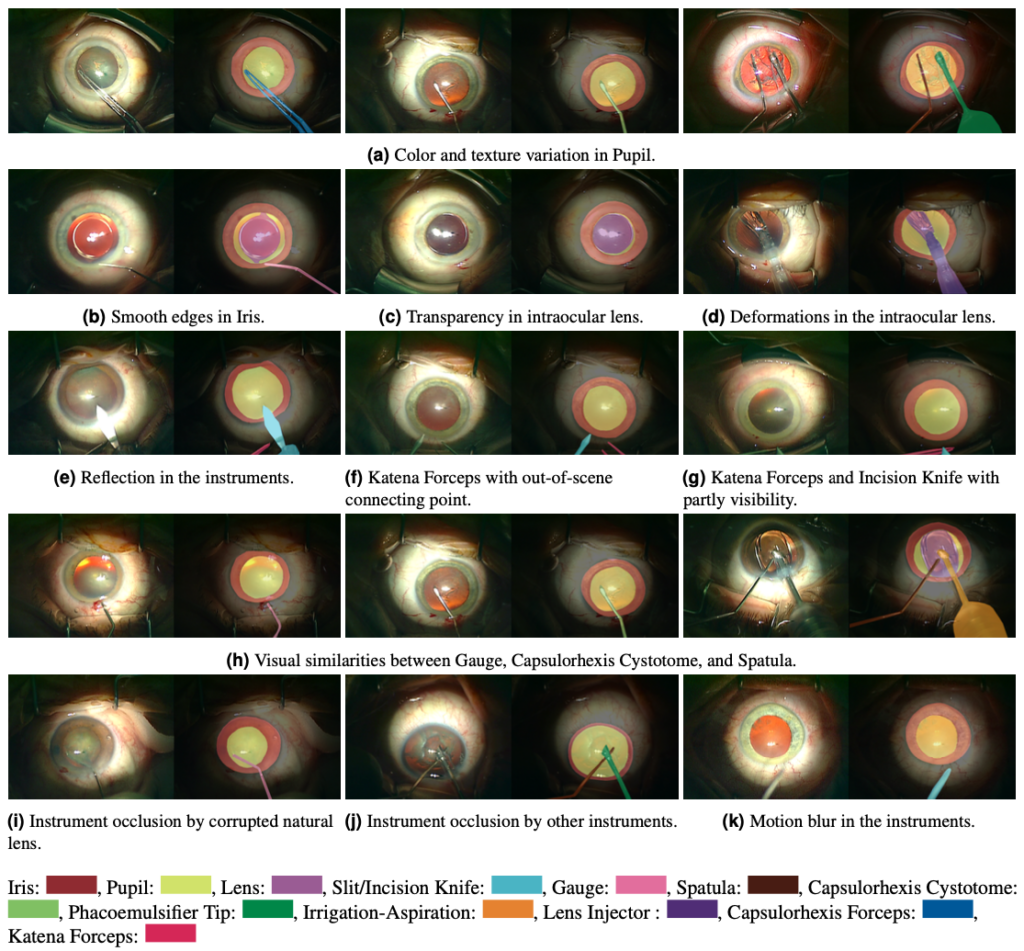
The Cataract-1K dataset consists of 1000 videos of cataract surgeries conducted in the eye clinic of Klinikum Klagenfurt from 2021 to 2023. The videos are recorded using a MediLive Trio Eye device mounted on a ZEISS OPMI Vario microscope. The Cataract-1K dataset comprises videos conducted by surgeons with a cumulative count of completed surgeries ranging from 1,000 to over 40,000 procedures. On average, the videos have a duration of 7.12 minutes, with a standard duration of 200 seconds. In addition to this large-scale dataset, we provide surgical phase annotations for 56 regular videos and relevant anatomical plus instrument pixel-level annotations for 2256 frames out of 30 cataract surgery videos. Furthermore, we provide a small subset of surgeries with two major irregularities, including “pupil reaction” and “IOL rotation,” to support further research on irregularity detection in cataract surgery. Except for the annotated videos and images, the remaining videos in the Cataract-1K dataset are encoded with a temporal resolution of 25 fps and a spatial resolution of 512×324.
More information can be found in our Nature Scientific Data paper.
The dataset can be downloaded from its GitHub page.
LensID: A CNN-RNN-Based Framework Towards Lens Irregularity Detection in Cataract Surgery Videos

This dataset includes video annotations and lens/pupil segmentations being created for our MICCAI 2021 paper: “LensID: A CNN-RNN-Based Framework Towards Lens Irregularity Detection in Cataract Surgery Videos”. It consists of three sub-datasets, namely:
- a large dataset containing the annotations for the lens implantation phase versus the rest of phases from 100 videos of cataract surgery. More specifically, it consists of 2040 video clips from 85 videos for training and 360 video clips from the other 15 videos for testing.
- a dataset containing the lens segmentation of 401 frames from 27 videos (292 images from 21 videos for training, and 109 images from six videos for testing)
- a dataset containing the pupil segmentation of 189 frames from 16 videos (141 frames from 13 videos for training, and 48 frames from three videos for testing).
Negin Ghamsarian, Mario Taschwer, Doris Putzgruber-Adamitsch, Stephanie Sarny, Yosuf El-Shabrawi and Klaus Schoeffmann. 2021. LensID: A CNN-RNN-Based Framework Towards Lens Irregularity Detection in Cataract Surgery Videos. In Proceedings of the 24th International Conference on Medical Image Computing & Computer Assisted Intervention 2021 (MICCAI 2021). 11 pages.
Link to MICCAI 2021 paper.
The dataset can be downloaded here.
Relevance Detection in Cataract Surgery Videos by Spatio-Temporal Action Localisation

This dataset contains the training and test data of the ICPR2020 paper mentioned below. In particular, it contains video segments from all cataract phases that were used to train the 1-vs-all models for the four relevant surgery phases below, which were evaluated with several different methods: (a) CNN, (b) CNN+LSTM, (c) CNN+GRU, (d) CNN+BiLSTM, (e) CNN+BiGRU.
- Rhexis
- Phacoemulsification phase
- Irrigation/aspiration (with viscoelastic suction)
- Lens implantation
Negin Ghamsarian, Mario Taschwer, Doris Putzgruber, Stephanie Sarny, and Klaus Schoeffmann. 2020. Relevance Detection in Cataract Surgery Videos by Spatio-Temporal Action Localization. Proceedings of the 25th International Conference on Pattern Recognition (ICPR 2020). IEEE, Los Alamitos, CA, USA, 8 pages (to appear).
The dataset can be downloaded here.
Relevance-Based Compression of Cataract Videos
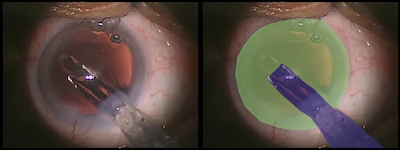 This dataset contains annotations of action and idle content in frames from cataract videos. More particular, it contains annotations of temporal segments where no instruments are used (idle phases) as well as action content (these are spatial annotations of the eye and instruments in frames).
This dataset contains annotations of action and idle content in frames from cataract videos. More particular, it contains annotations of temporal segments where no instruments are used (idle phases) as well as action content (these are spatial annotations of the eye and instruments in frames).
For the first set of annotations, 22 videos are selected from the released Cataract-101 dataset. All frames of 22 videos from the dataset are annotated and categorized as idle or action frame. From these annotations, 18 videos are randomly selected for training and the remaining videos are used for testing. Subsequently, 500 idle and 500 action frames are uniformly sampled from each video, composing 9000 frames per class in the training set and 2000 frames per class in the testing set.
The second set of annotations includes the manual annotations of the cornea and instruments using the open-source Supervisely platform. We have annotated the cornea of 262 frames from 11 cataract surgery videos for the eye segmentation task, and the instruments of 216 frames from the same videos for the instrument segmentation task.
The dataset has been released as an add-on to our ACM Multimedia 2020 paper:
N. Ghamsarian, H. Amirpour, C. Timmerrer, M. Taschwer, K. Schoeffmann. 2020. Relevance-Based Compression of Cataract Surgery Videos Using Convolutional Neural Networks. In Proceedings of the ACM International Conference on Multimedia (ACMMM2020), pages 1-9. ACM, 2020 (to appear)
Please download the dataset here.
Tool Segmentation in Cataract Surgery Videos
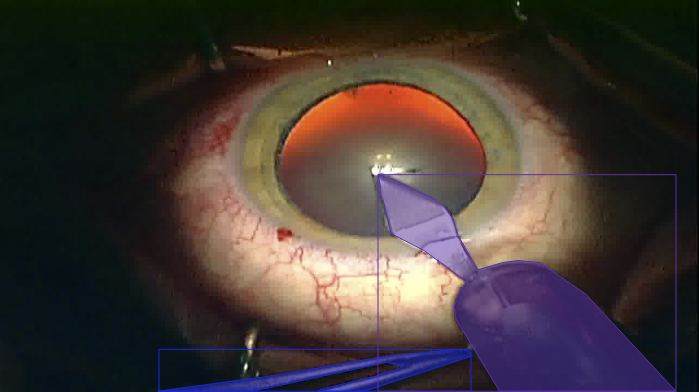 This dataset contains bounding-box and mask segmentations for typical instruments in cataract surgery, sampled from 393 selected frames of the Cataract-101 video dataset as well as 4738 images of the CaDIS dataset. An evaluation for this dataset can be found in the following CBMS 2020 paper:
This dataset contains bounding-box and mask segmentations for typical instruments in cataract surgery, sampled from 393 selected frames of the Cataract-101 video dataset as well as 4738 images of the CaDIS dataset. An evaluation for this dataset can be found in the following CBMS 2020 paper:
Markus Fox, Mario Taschwer, Klaus Schoeffmann. 2020. Pixel-Based Tool Segmentation in Cataract Surgery Videos with Mask R-CNN. Proceedings of the 33rd International Symposium on Computer Based Medical Systems (CBMS), IEEE, Los Alamitos, 4 pages.
The dataset is available for download here.
Iris and Pupil Segmentation in Cataract Surgery Videos
 This dataset contains mask segmentations for Iris and Pupil in 82 frames sampled from videos of the Cataract-101 video dataset. An evaluation for automatic Iris and Pupil segmentation can be found in our ISBI 2020 workshop paper:
This dataset contains mask segmentations for Iris and Pupil in 82 frames sampled from videos of the Cataract-101 video dataset. An evaluation for automatic Iris and Pupil segmentation can be found in our ISBI 2020 workshop paper:
Natalia Sokolova, Mario Taschwer, Stephanie Sarny, Doris Putzgruber-Adamitsch, Klaus Schoeffmann. 2020. Pixel-Based Iris and Pupil Segmentation in Cataract Surgery Videos Using Mask R-CNN. Proceedings in IEEE International Symposium on Biomedical Imaging Workshops. IEEE, Los Alamitos, CA, USA, 4 pages.
The dataset is available for download here.
GLENDA – The ITEC Gynecologic Laparoscopy Endometriosis Dataset
GLENDA (Gynecologic Laparoscopy ENdometriosis DAtaset) comprises over 25 000 images taken from 400+ gynecologic laparoscopy surgeries and is purposefully created to be utilized for a variety of automatic content analysis problems in the context of Endometriosis recognition. It contains about 12000 frames showing endometriosis of varying severity (peritoneum, ovary, uterus, and deep infiltrated endometriosis) as well as about 13000 frames showing no endometriosis. Many frames with endometriosis further contain region-based and temporal expert annotations.
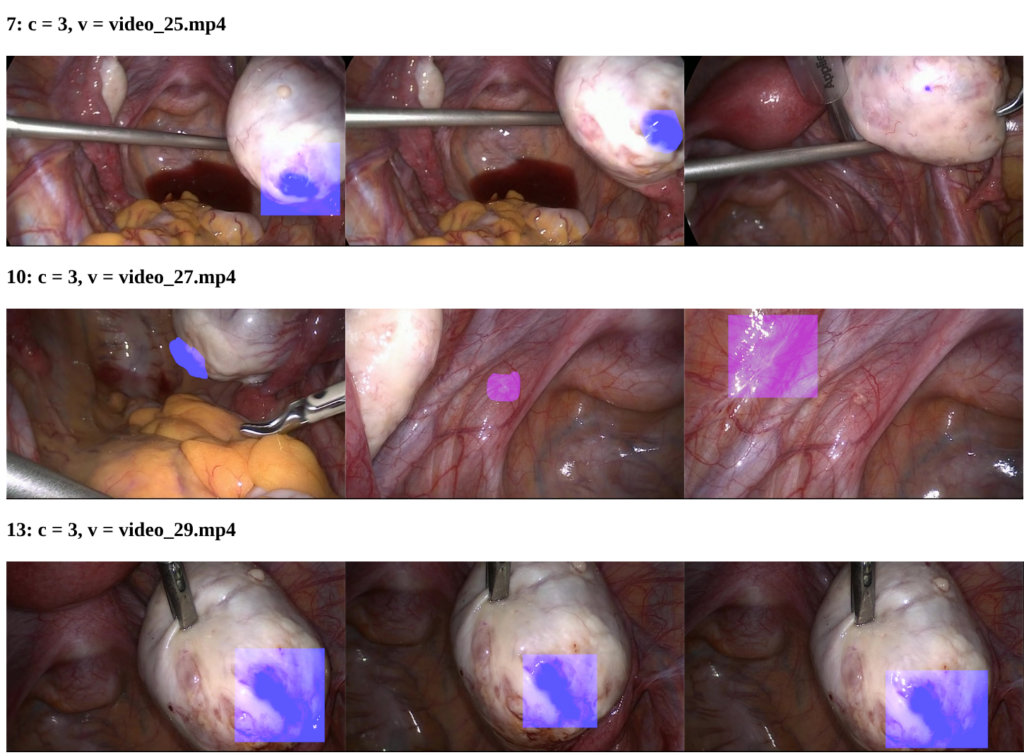
The GLENDA dataset is available for download here.
V3C1 Analysis Data
Results of content analysis on the V3C1 dataset can be downloaded from my GitHub repository. An overview and description of the analysis data can be found in our SIGMM Records article. Thanks a lot also to Luca Rossetto for providing the second part of the analysis results.
V3C1 Mirror (Vimeo Creative Commons License)
We provide a mirror of the V3C1 dataset in collaboration with NIST/TRECVID, which is used for the Video Browser Showdown as well as for the TRECVID Ad-Hoc Video Search (AVS) Task (thanks a lot to Luca Rossetto). This first part of the V3C dataset consists of 7475 video files, amounting for 1000h of video content (1,082,659 predefined segments) and 1.3 TB in size. In order to download the dataset, please complete this data agreement form and send a scan to angela.ellis@nist.gov with CC to gawad@nist.gov and ks@itec.aau.at. You will be provided with an FTP-server link for downloading the data.
LapGyn4 Gynecologic Laparoscopy Dataset

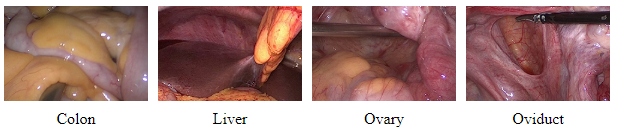
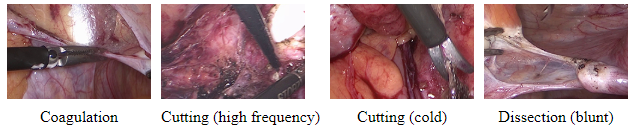
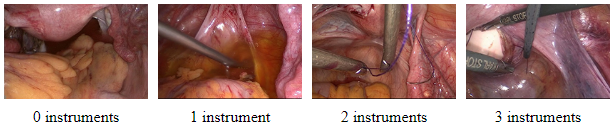
The ITEC LapGyn4 Gynecologic Laparoscopy Image Dataset actually comprises four individual datasets:
- surgical actions
- anatomical structures
- actions on anatomy
- instrument count
The dataset was collected from 500+ gynecologic laparoscopic surgeries for the task of automatic content analysis, as described in detail in the corresponding paper presented at MMSYS 2018 (if you use our dataset, please cite this paper).
The ITEC LapGyn4 dataset is available here.
Cataract-101 Video Dataset


The ITEC Cataract-101 dataset consists of videos from 101 cataract surgeries, annotated with different operation phases that were performed by four different surgeons over a period of 9 months. These surgeons are grouped into moderately experienced and highly experienced surgeons (assistant vs. senior physicians), providing the basis for experience-based video analytics, as described in detail in the corresponding paper presented at MMSYS 2018 (if you use our dataset, please cite this paper) .
The ITEC Cataract-101 dataset is available for download here.
Cataract-21 Video Dataset
The dataset contains 21 video recordings of cataract surgeries. The dataset is divided into a training part consisting of 17 videos and a validation part consisting of 4 videos. For each video a CSV file with ground-truth annotations is provided, linking each frame number to one of ten classes (operation phases) listed above. The ground-truth annotation has been done by medical experts of Klinikum Klagenfurt. Please note that parts of video recordings that do not belong to any of the classes are labelled with “not_initialized” (in particular, the part before the first phase “Incision”).
The ITEC Cataract-21 dataset is available for download here.
SurgicalActions160
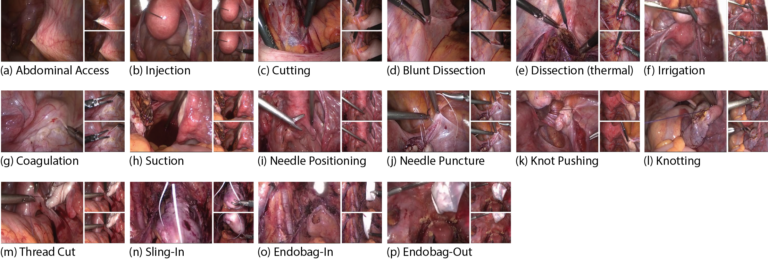
The ITEC SurgicalActions160 dataset consists of short video clips representing 16 typical actions in gynecologic laparoscopy, which have been compiled from different surgeries. For each action class there are exactly 10 example clips.
The SurgicalActions160 dataset is available for download here.
More information about the dataset can be found in our MTAP paper (if you use our dataset, please cite this paper):
Klaus Schoeffmann, Heinrich Husslein, Sabrina Kletz, Stefan Petscharnig, Bernd Münzer, and Christian Beecks. Video Retrieval in Laparoscopic Video Recordings with Dynamic Content Descriptors, in Multimedia Tools and Applications (MTAP), 2018, pp. 1-18, online first.